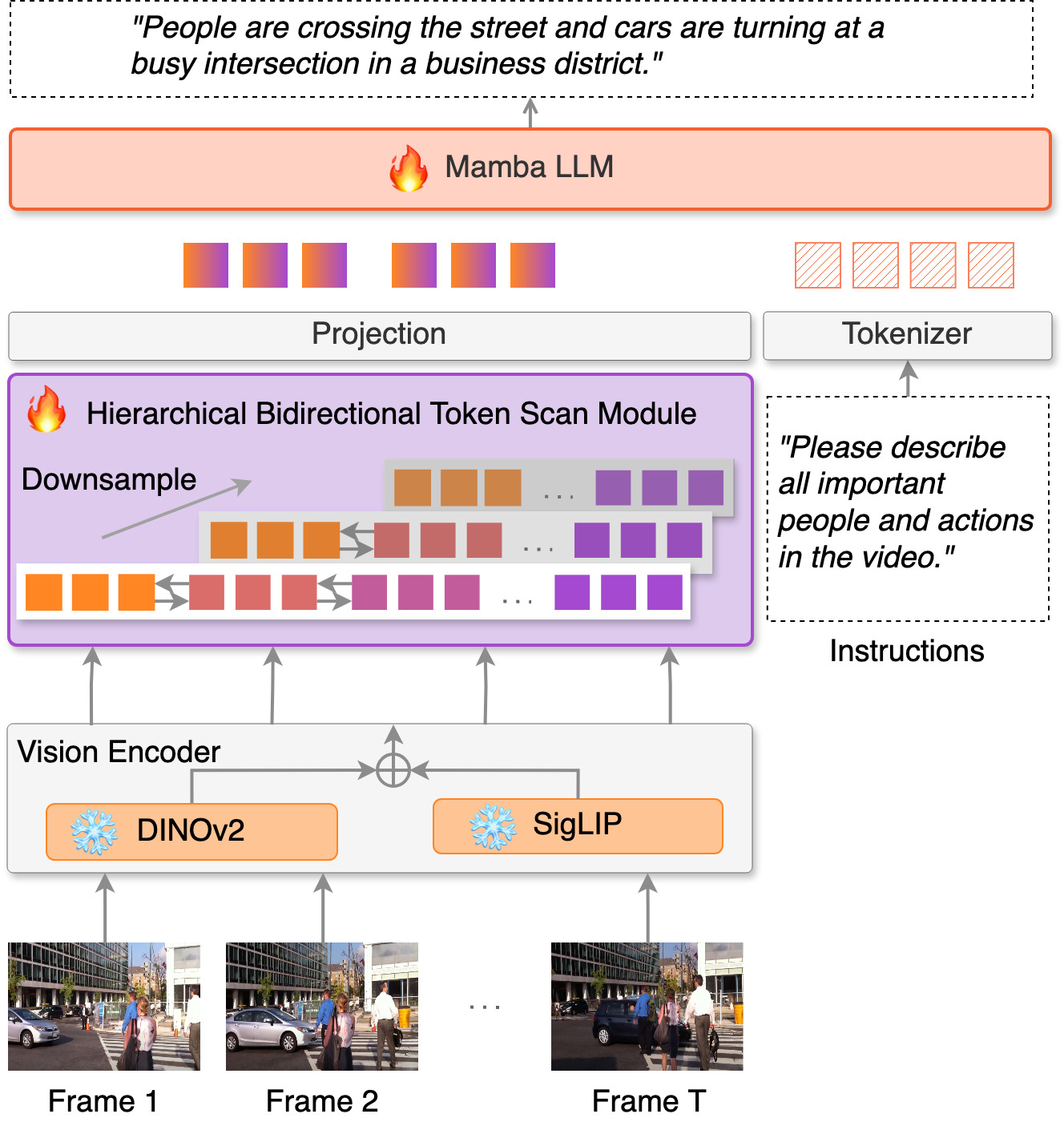
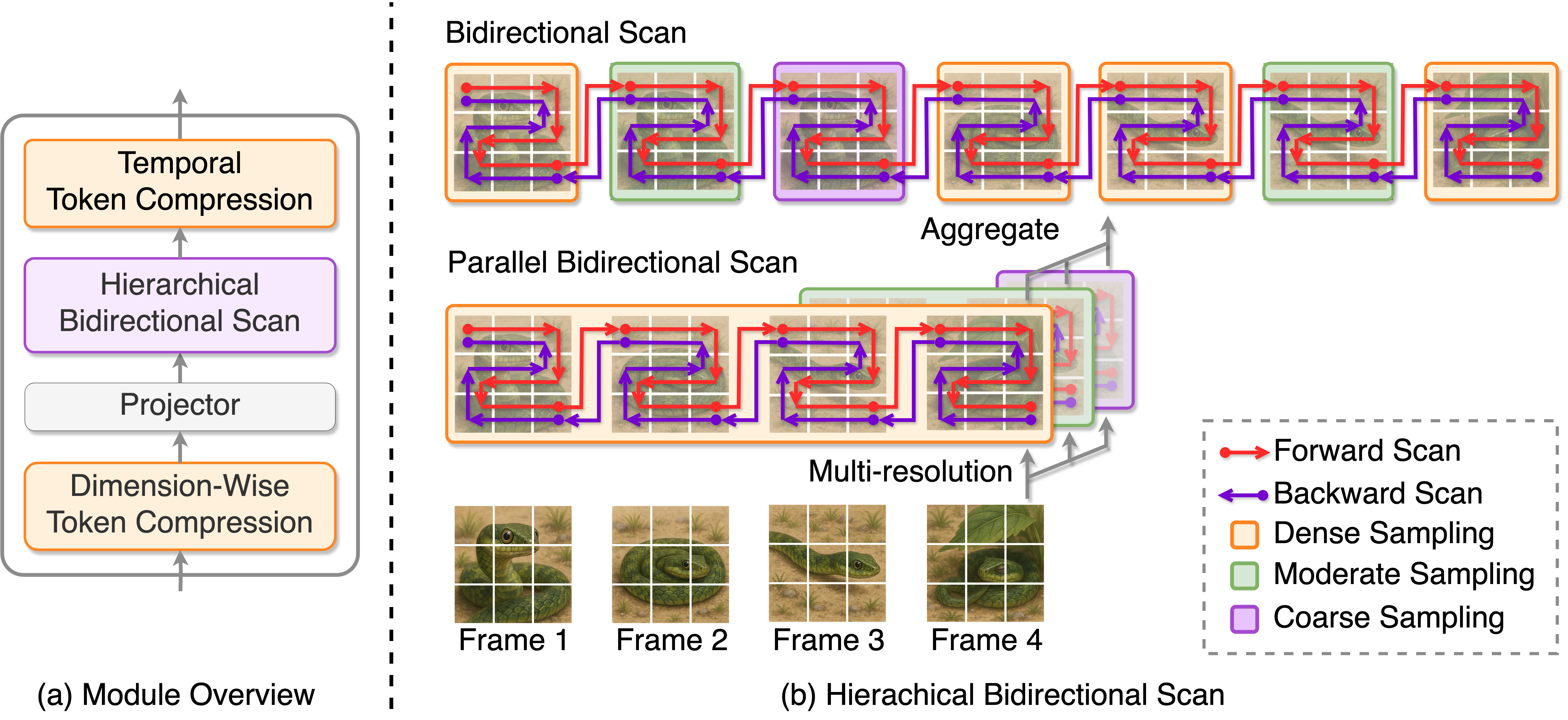
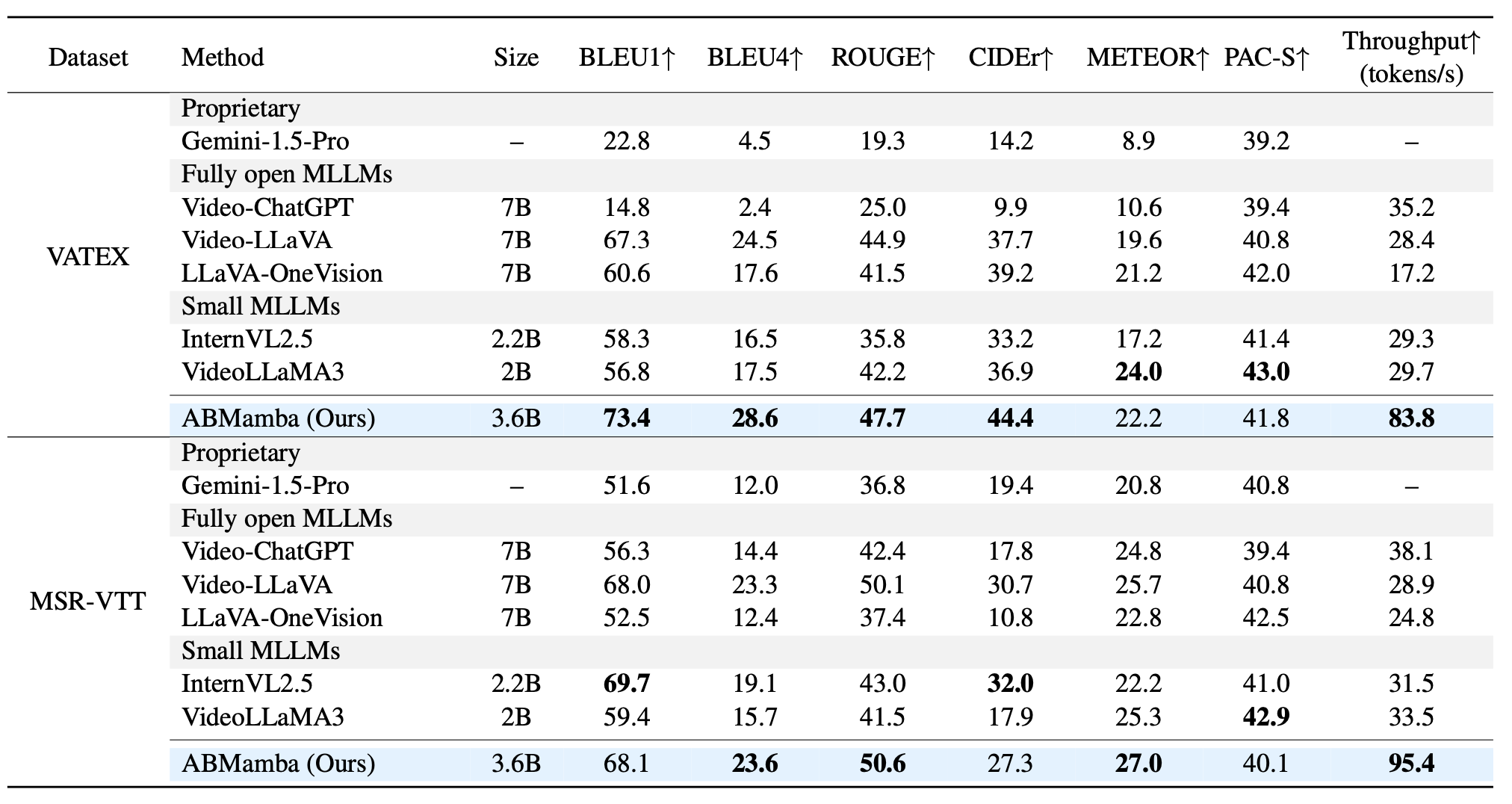
In this study, we focus on video captioning by fully open multimodal large language models (MLLMs). The comprehension of visual sequences is challenging because of their intricate temporal dependencies and substantial sequence length. The core attention mechanisms of existing Transformer-based approaches scale quadratically with the sequence length, making them computationally prohibitive. To address these limitations, we propose Aligned Hierarchical Bidirectional Scan Mamba (ABMamba), a fully open MLLM with linear computational complexity that enables the scalable processing of video sequences. ABMamba extends Deep State Space Models as its language backbone, replacing the costly quadratic attention mechanisms, and employs a novel Aligned Hierarchical Bidirectional Scan module that processes videos across multiple temporal resolutions. On standard video captioning benchmarks such as VATEX and MSR-VTT, ABMamba demonstrates competitive performance compared to typical MLLMs while achieving approximately three times higher throughput.